前言
CS61C的笔记。以下描述的所有内容基于RV32(RISC-V的32位变体)。 CS61C的视频:Youtube
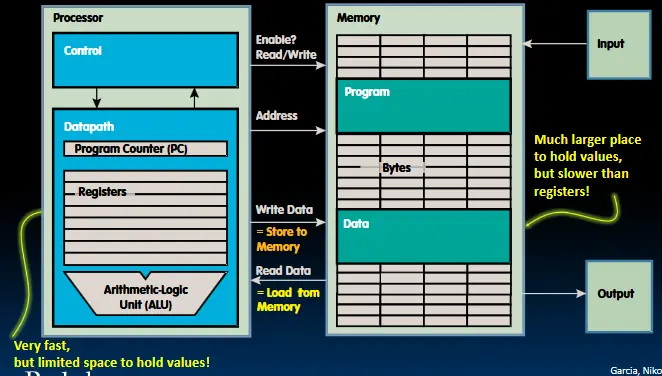
寄存器
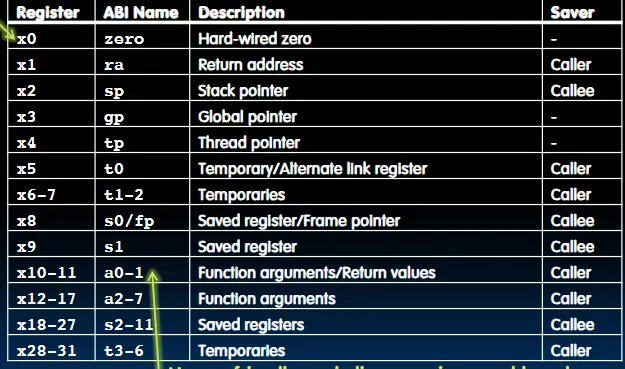
RISC-V中有32个寄存器,每个寄存器的位宽为32。命名为x0-x31,其中x0永远存储0值(通过硬连线到地)。其中x10-x17又被命名为a0-a7,作为函数调用的参数寄存器。
汇编
关于RISC-V指令我发现一个很实用的项目,他将RV32I的指令和汇编伪指令做成了tldr库。安装后可以方便的查询指令的用法。
加减法
add
加法。
- 示例:
add x1,x2,x3(in RISC-V) - 等同于:
a = b + c(in C)
sub
减法。
- 示例:
sub x3,x4,x5(in RISC-V) - 等同于:
d = e - f(in C)
addi
立即数加法。
- 示例:
addi x3,x4,10(in RISC-V) - 等同于:
f = g + 10(in C) 不存在立即数减法指令,将立即数设置为负数即可实现减法。 它可以用内存操作指令配合加法指令来替代,但我们仍然需要它。因为立即数加法非常常用。
内存操作
内存
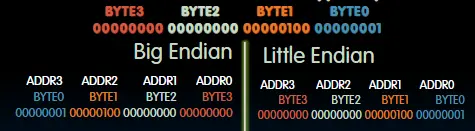
内存按照字(words,4 bytes = 1 words)组织。数据遵循小端模式,高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中。
lw
从内存读取一个字到寄存器。 示例:
int A[100];
g = h + A[3];
lw x10, 12(x15)
add x11, x12, x10
其中x15表示A所在的地址,12(字节)为偏移量。由于内存按照字(4字节)组织,故A[3]便是由A的地址偏移3个字得到的。偏移量必须是4的倍数。
sw
从寄存器保存一个字到内存。 示例:
int A[100];
A[10] = h + A[3];
lw x10, 12(x15)
add x11, x12, x10
sw x10, 40(x15)
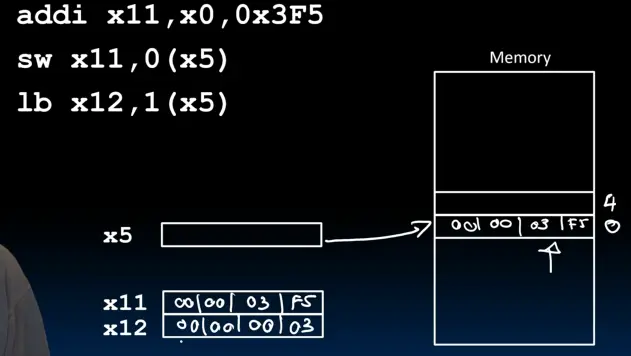
lb
从内存读取一个字节到寄存器。
lb x10, 3(x11) # 3为3个字节的偏移量
这个字节会被写入到x10的最低字节位置。
大多数情况下,我们操作的是有符号数。如果我们将一个字节读取到x10的最低字节的位置,那么此时高字节都为0,就无法确定这个数的符号是什么了。因此,在把这个字节读取到低字节的位置同时,要记下它的符号,并把它放在高字节的所有位。这个过程称为符号扩展(Sign Extension)。
 示例:
示例:
lbu
如果不想做符号扩展,或者操作的是无符号数,可以使用这个指令。它的语法与lbu完全相同。
分支
beq
beq = branch equal
beq reg1, reg2, L1
如果reg1的值等于reg2的值,则跳转到标签L1。
bne
bne = branch not equal
bne reg1, reg2, L1
如果reg1的值不等于reg2的值,则跳转到标签L1。
blt
blt = branch less than
blt reg1, reg2, L1
如果reg1的值小于reg2的值,则跳转到标签L1。
bge
bge = branch greater or equal
bge reg1, reg2, L1
如果reg1的值大于等于reg2的值,则跳转到标签L1。
bltu
blt的无符号数版本。
bgeu
bge的无符号数版本。
j
j = jump
j L1
跳转到标签L1。
分支的示例
if (i == j)
f = g + h;
else
f = g - h;
bne x13, x14, Else
add x10, x11, x12
j Exit # 重要
Else:
sub x10,x11,x12
Exit:
循环的示例
int A[20];
int sum = 0;
for (int i=0;i < 20;i++)
sum += A[i];
add x9, x8, x0 # x9=&A[0]
add x10, x0, x0 # sum = 0
add x11, x0, x0 # i = 0
addi x13, x0, 20
Loop:
bge x11, x13, Done
lw x12, 0(x9)
add x10, x10, x12
addi x9, x9, 4 # &A[i+1]
addi x11, x11, 1 # i++
j Loop
Done:
逻辑运算
按位与
and x5, x6, x7 # x5 = x6 & x7
andi x5, x6, 3 # x5 = x6 & 3
按位或
or x5, x6, x7 # x5 = x6 | x7
ori x5, x6, 3 # x5 = x6 | 3
按位异或
xor x5, x6, x7 # x5 = x6 ^ x7
xori x5, x6, 3 # x5 = x6 ^ 3
按位取反
xori x5, x6, 0 # x5 = x6 ^ -1
位移
sll x11, x12, x13 # x11 = x12 << x13
slli x11, x12, 2 # x11 = x12 << 2
srl x11, x12, x13 # x11 = x12 >> x13
srli x11, x12, 2 # x11 = x12 >> 2
对于有符号数来说,使用算术移位会保留符号数:
sra x10, x11, x12 # x10 = x11 >> x12
srai x10, x11, 4 # x10 = x11 >> 4
不存在算术左移,因为逻辑左移和它的行为是一样的。
伪指令
mv rd, rs = addi rd, rs, 0
li rd, 13 = addi rd, x0, 13
nop = addi x0, x0, 0
函数调用
- 将参数放在函数可以访问到的地方(特定寄存器)。
- 把控制权交给函数。(
jal) - 访问函数需要的存储资源。
- 执行函数。
- 把返回值放在调用函数的代码可以访问到的地方,并且恢复所有用到的寄存器,释放存储资源。
- 把控制权交回开始的地方。
- a0-a7(x10-x17): 用来传递函数参数,其中
a0-a1用来返回值。 - ra(x1):用来返回地址回到最开始的地方。
- s0-s1(x8-x9),s2-s11(x18-x27):保留的寄存器。
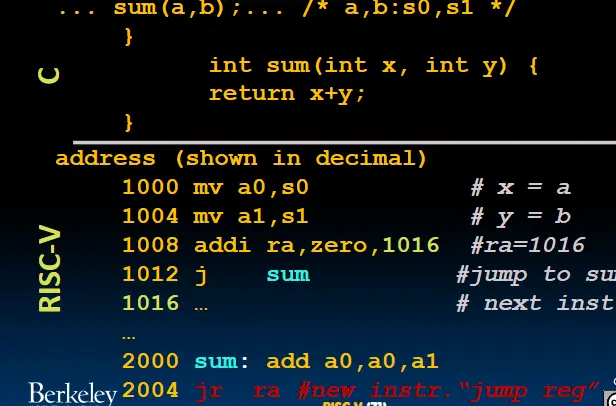 其中
其中
addi ra, zero, 1016
j sum
等同于
jal sum
ret = jr ra
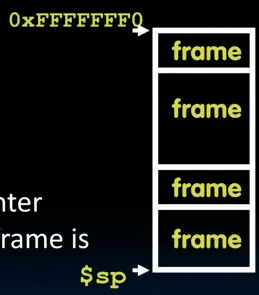
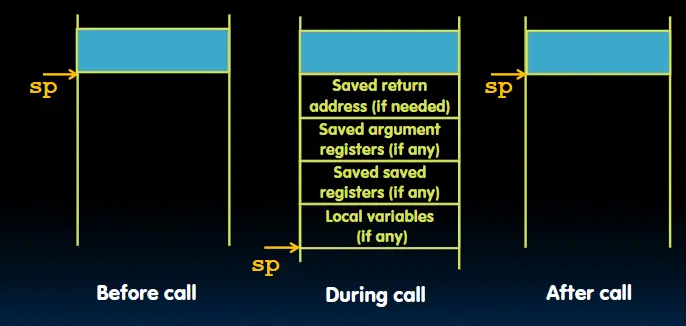
堆栈
- 需要有一个地方用来存放寄存器中的旧值,一个理想的地方是栈(LIFO队列)。
sp(x2)是栈指针在的寄存器。- 栈从内存空间的顶部开始并向下增长。 (当增加栈时,减小栈指针的地址) 每个函数调用时都对应有一个栈帧,堆栈帧包含:
- 返回地址
- 参数
- 其他本地变量的空间
函数调用的示例
int Leaf(int g, int h, int i, int j){
int f;
f = (g + h) - (i + j);
return f;
}
- 参数
g,h,i,j应当放在寄存器a0,a1,a2,a3中,返回值f应当放在寄存器f0中。 - 假设有一个临时寄存器(
s1)用来存放f。
Leaf:
addi sp, sp, -8 # 为两个寄存器的旧值留出空间
sw s1, 4(sp)
sw s0, 0(sp)
add s0, a0, a1
add s1, a2, a3
sub a0, s0, s1
lw s0, 0(sp)
lw s1, 4(sp)
addi sp, sp, 8 # 将栈调整回原来的空间
ret
嵌套调用
如果一个函数调用了另一个函数,那么这两个函数都有参数与返回值需要存在特定寄存器中,从而造成了冲突。为了解决这个问题,RISC-V将寄存器分为两类,一类是在函数调用之间保留的寄存器,调用者可以依赖这些值保持不变,另一类是临时的寄存器,调用函数前需要保存这些寄存器的值到栈。
内存分配
C语言中有两类变量:automatic和static
- automatic变量只存在与函数内部,在进入函数时被创建,离开函数时被释放。
- staitc变量存在于整个程序的生命周期中。 C程序运行时,有三个内存区域被分配:Static、Heap、Stack
- Staic:一次声明的变量,程序运行时用远存在。
- Heap:被
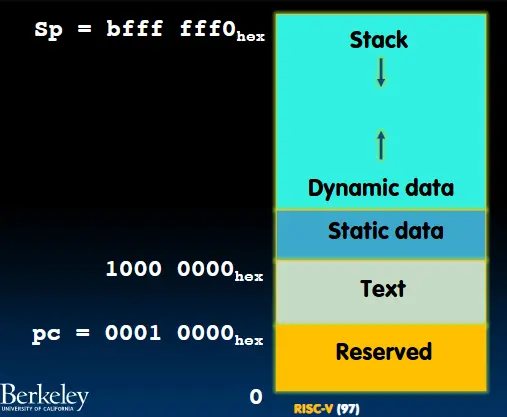
malloc动态声明的变量。 - Stack:函数运行期间声明的变量。 在RICV-中,栈在内存中的位置是哪?
- 不同的RISC-V变体的内存结构不同。
- 栈从内存的顶部向低内存地址延伸。
- 栈的起始内存地址:
bfff_fff0(hex) - 栈必须与16位边界对齐
- 栈的起始内存地址:
- RV32程序(Text)处在靠近内存底部的地方(但不是最底下,那里有特殊的东西存在,像是IO设备)。
0001_0000(hex)
- 常量或是静态变量存在于程序的上方。
- 全局指针(
gp=1000_0000(hex))指定了静态变量(就像sp指定stack那样)
- 全局指针(
- 堆处于栈(常量或静态变量)的上方。
嵌套调用的示例
int sumSquare(int x, int y) {
return mult(x, x) + y
}
sumSquare:
addi sp, sp, -8 # >
sw ra, 4(sp) # 保存要返回到的地址 > 入栈
sw a1, 0(sp) # 保存y >
mv a1, a0
jal mult
lw a1, 0(sp) # 恢复y >
add a0, a0, a1
lw ra, 4(sp) # 得到返回地址 > 出栈
addi sp, sp, 8 # 释放栈上的空间 >
ret
总结
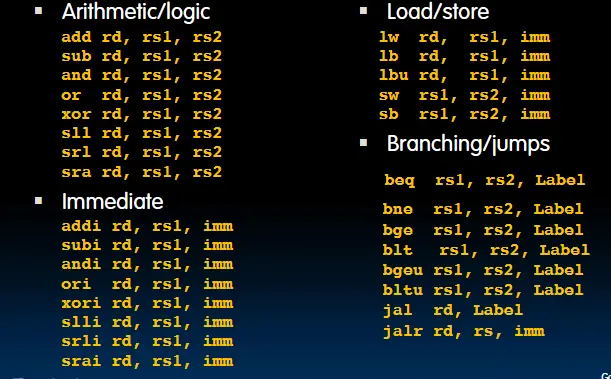
指令
- R型指令:用于寄存器与寄存器之间的算术、逻辑运算的指令。
- I型指令:用于寄存器与立即数之间的算术、逻辑运算,以及加载的指令。
- S型指令:用于存储的指令。
- B型指令:用于分支的指令。
- U型指令:用于大立即数的指令。
- J型指令:用于跳转的指令。
R型指令

- opcode:所有R型指令的opcode都为
0110011。 - rd:目标寄存器。
- rs1, rs2:源寄存器。
I型指令
立即数指令

- opcode:所有立即数相关指令的opcode都为
0010011。 - rs1:源寄存器。
- rd:目标寄存器。
- imm:立即数。
- funct3:用来表示具体执行哪条指令。
 其中
其中shamt表示移位的量,由于超过32位的移位是无意义的,故将前imm的前几位固定。
加载指令
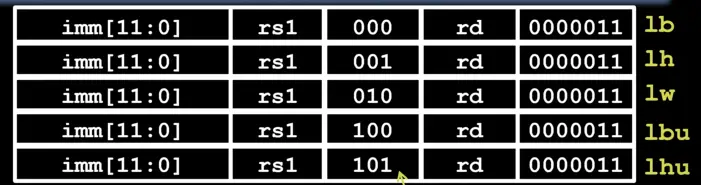
- opcode:所有加载指令的opcode都为
0000011。 - rs1:内存基地址。
- rd:目标寄存器。
- imm:偏移量。
- funct3:用来表示具体执行哪条指令。
S型指令

- opcode:所有存储指令的opcode都为
0100011。 - imm,Imm:偏移量。

B型指令
- 当没有分支发生时:
- PC = PC + 4
- 当分支发生时:
- PC = PC + immediate*2 (immediate可正可负)
- 为什么不是乘4?因为RV32支持16位的压缩指令
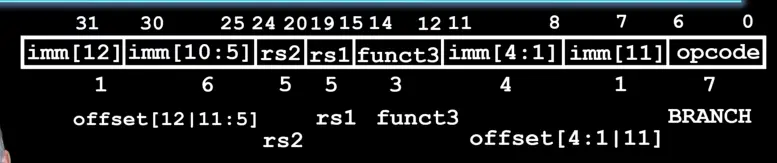
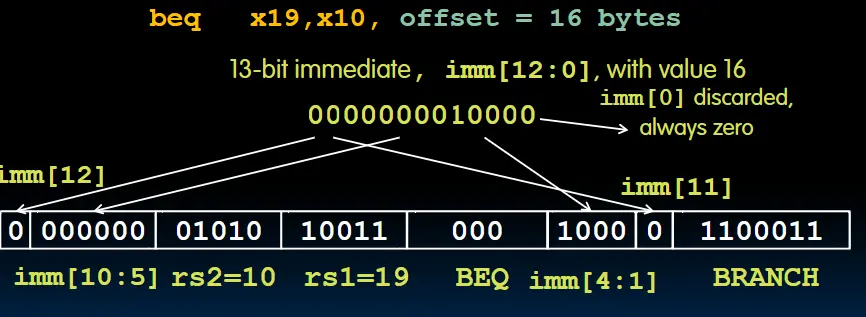
- opcode:所有B型指令的opcode都为
1100011。 - immediate:偏移量。值为-4096~+4094。它实际上是一个13位长的数,它的最低位始终为0。如果需要大于这个范围的偏移量,可以通过将分支指令调整为分支+跳转指令的写法,跳转指令有着更大的偏移量范围。
 分支命令的示例:
分支命令的示例:
Loop: beq x19, x10, End
add x18, x18, x10
addi x19, x19, -1
j Loop
End:
在这个示例中,immediate = 16。
U型指令
B型指令的偏移量是12位的,可以用U型指令增加剩下的20位。

- opcode:所有U型指令的opcode都为
0110111。 - imm:偏移量。
U型指令的示例(将32位立即数加载到寄存器中):
lui x10, 0x87654 # x10 = 0x87654000
addi x10, x10, 0x321 # = x10 = 0x87654321
需要注意的问题:
lui x10, 0xDEADB
addi x10, x10, 0xEEF
x10中的数最终为0xDEADAEEF。这是因为addi指令会对0xEEF进行符号扩展,导致高20位减少。 正确的做法是在使用lui指令时就将那20位加1,但不必自己这么做,伪指令可以帮我们做:
li x10, 0xDEADBEEF
补充:auipc指令
auipc rd, immediate
将20位立即数加到PC,并写入到rd中。 把Label的地址放入x10:
Label: auipc x10, 0
J型指令

- opcode:固定为
1101111。 - rd:jal指令会将PC+4(返回地址)保存到rd中。
- imm:偏移量。将PC设为PC + 偏移量。它是21位长的,最低位为0。 J型指令实际上只有jal这一个,其他指令比如j和jr都是伪指令。
j Label = jal x0, Label
jalr:并非J型指令
 jalr指令实际上是I型指令。
jalr指令实际上是I型指令。
- opcode:
1100 - rd:将PC+4保存到rd中。
- imm:偏移量。PC = rs1 + immediate。偏移量的最低为应该为零以确保跳转到偶数地址。
ret = jr ra = jalr x0, ra, 0
# 跳转到32位绝对地址
lui x1, <high20bits>
jalr ra, x1, <low12bits>
# 跳转到32位相对地址
auipc x1, <high20bits>
jalr x0, x1, <low12bits>
编译、汇编、链接和加载
编译器
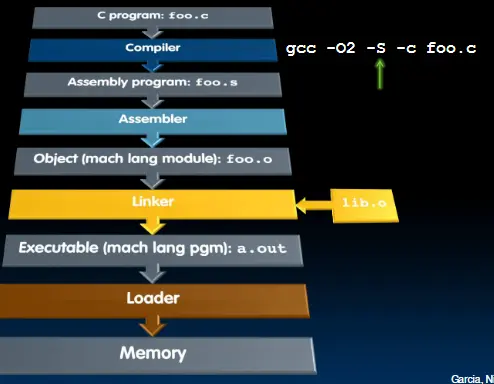
汇编器
.text和.data用于指定代码和数据的存放位置。.global用于声明全局符号。.string用于定义字符串。.word用于定义字(word)数据。 汇编后生成的.o文件可能包含以下部分:
- ELF 头 :描述文件的基本信息。
- 节头表:描述
.text、.data、.symtab等节的信息。 .text节:存储main函数的机器码。.data节:存储字符串"Hello, World!"和数组[1, 2, 3]。- 重定位信息:标识需要被修整的代码。比如调用了外部函数的代码。
- 调试信息
链接器
不需要重新定位的代码:
- PC相对位置的寻址(beq, bne, jal;auipc/addi) 需要重新定位的代码:
- 绝对位置的函数寻址(auipc/jalr)
- 外部函数调用(auipc/jalr)
- 静态资源调用(lui/addi)
对于RV32,链接器认定程序的第一个字节位于0x10000(虚拟内存)。
动态链接与静态链接
盛行的链接方法是在机器码阶段进行动态链接。
- 静态链接(Static Linking):
- 在编译时将所有的库代码和程序代码合并到一个单独的可执行文件中。
- 可执行文件不依赖外部的库文件。
- 动态链接(Dynamic Linking):
- 在编译时只记录程序所需的库信息,而不将库代码直接嵌入可执行文件。
- 在程序运行时,由操作系统的动态链接器加载所需的库。 盛行的链接方法是在机器码阶段进行动态链接。现在计算机存储空间已经变得巨大且廉价,动态链接所节省的存储空间似乎逐渐不再是一个优点,而动态链接带来的问题逐渐令人无法忍受。现在在Linux系统上虽然动态链接依然是主流,但已经有越来越多软件(尤其是在Windows系统上)采用静态链接。
| 特性 | 静态链接 | 动态链接 |
|---|---|---|
| 文件大小 | 较大 | 较小 |
| 内存占用 | 较高 | 较低 |
| 加载速度 | 较快 | 较慢 |
| 更新维护 | 需要重新编译 | 只需替换库文件 |
| 兼容性 | 较好 | 依赖系统环境 |
| 安全性 | 较高 | 较低 |
| 适用场景 | 嵌入式、独立工具 | 桌面、服务器、共享库场景 |
加载器
加载器的作用:
- 读取可执行文件的文件头来决定程序需要的空间大小
- 创建地址空间
- 将指令和数据从可执行文件中复制到新创建的地址空间中
- 把运行程序时提供的参数传递给程序(暂存在栈上)
- 初始化寄存器
- 跳转到程序开始位置,并且把参数从栈上复制到寄存器。设置PC。
同步数字系统
状态与状态机
D触发器
一个N位的寄存器由N个并行的D触发器组成。 D触发器的特征方程: $Q_{next} = D$ D触发器的电路符号:
┌───┐
D ──┤ ├─▶ Q
CLK─┤ ├─▶ Q'
└───┘
- D(Data):数据输入
- CLK(Clock):时钟输入(上升沿或下降沿触发)
- Q/Q’:互补输出(Q为数据存储值,Q’为反相输出)
- 可选控制端:异步置位(SET)、复位(RESET)
以上升沿触发的D触发器为例,当时钟处于上升沿时,D触发器从D中获得数据并输出到Q。从D获取数据时,D应当是稳定了一段时间,这段时间被称为保持时间。
示例波形:

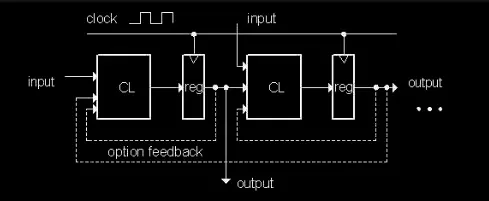
流水线
流水线的示例
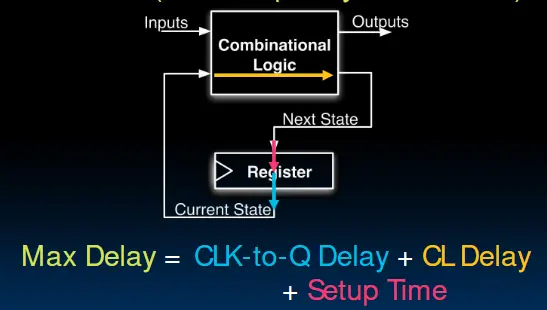 在这样的电路中,D触发器的时钟频率收到了Max Delay的限制。如果时钟周期小于Max Delay,那么在第二次时钟沿上升来临时,D触发器就无法捕获到正确的数据。如果想要加快时钟,可以插入更多寄存器,形成流水线结构。
在这样的电路中,D触发器的时钟频率收到了Max Delay的限制。如果时钟周期小于Max Delay,那么在第二次时钟沿上升来临时,D触发器就无法捕获到正确的数据。如果想要加快时钟,可以插入更多寄存器,形成流水线结构。

流水线结构的原理
1. 关键路径决定时钟频率
- 组合逻辑的传播延迟:任何组合逻辑电路(如加法器、乘法器)的运算时间由其最长路径的延迟(即关键路径)决定。
- 时钟周期约束:系统最大时钟频率 必须满足:$T_{clock} \geq t_{criticalPath}+t_{setup}+t_{clockSkew}$ 2. 流水线的核心思想:分割关键路径
- 插入寄存器分割逻辑:将原本的单级组合逻辑分割为多级,每级之间插入寄存器(D触发器)。
- 每级逻辑的延迟降低:
- 若原始关键路径延迟为$t_{criticalPath}$,分割为$N$级流水线后,每级的延迟降至约$t_{criticalPath}/N$(假设逻辑均匀分割)。
- 时钟频率提升:$T_{clock} \geq t_{criticalPath}/N+t_{setup}+t_{clockSkew}$ 以上是理想的状态,但实际上增加寄存器本身会增加寄存器的建立时间和传播延迟,因此会稍微降低频率提升的幅度。另外流水线并不是越长越好,更长的流水线可能会导致更频繁的流水线冲突,比如Intel Pentium 4 CPU具有31级流水线,因而能达到高达3.8Ghz的时钟频率(在那个年代已经是非常高的),但实际的功耗和分支预测失败代价极高。现代的CPU如AMD Zen系列采用的是19级的流水线,在时钟频率和分支预测之间取得了不错的平衡。
有限状态机
有限状态机的示例:检测输入数据是否有连续的3个1出现

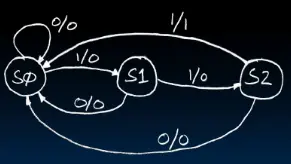 图中S0、S1和S2分别代表三种状态,他们直接的有向连线代表状态机转换状态的条件和方向。
图中S0、S1和S2分别代表三种状态,他们直接的有向连线代表状态机转换状态的条件和方向。
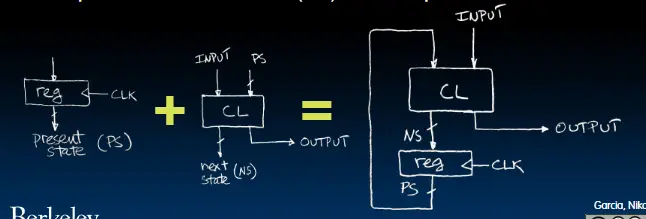
同步数字系统的模型
组合逻辑
布尔代数
符号:
- “$+$”:OR
- “$\cdot$”:AND
- “$\bar x$”:NOT
示例:
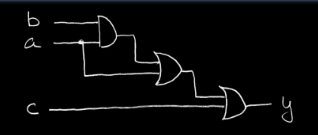 $$
\begin{align}
y = a \cdot b + a + c
\\ y = a \cdot (b+1) + c
\\ y = a \cdot 1 + c
\\ y = a + c
\end{align}
$$
一些定律:
$$
\begin{align}
y = a \cdot b + a + c
\\ y = a \cdot (b+1) + c
\\ y = a \cdot 1 + c
\\ y = a + c
\end{align}
$$
一些定律:
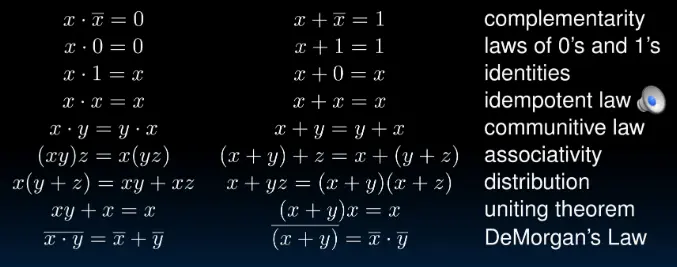
规范形式

组合逻辑模块
多路复用器

算术逻辑单元
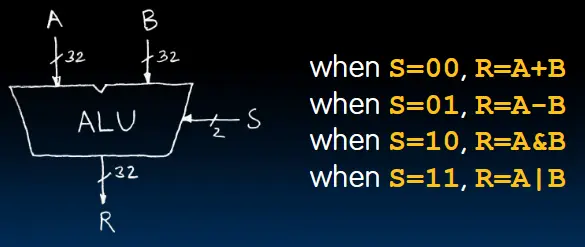
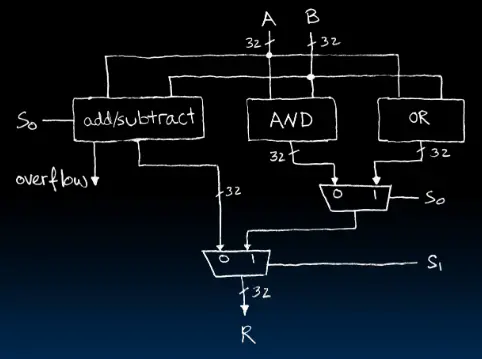
加/减法器
1位加法器的设计:
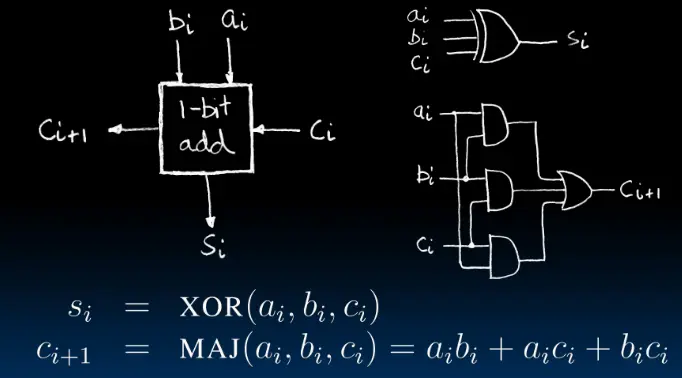 n位加法器就是将n个1位加法器串联起来。
n位加法器就是将n个1位加法器串联起来。
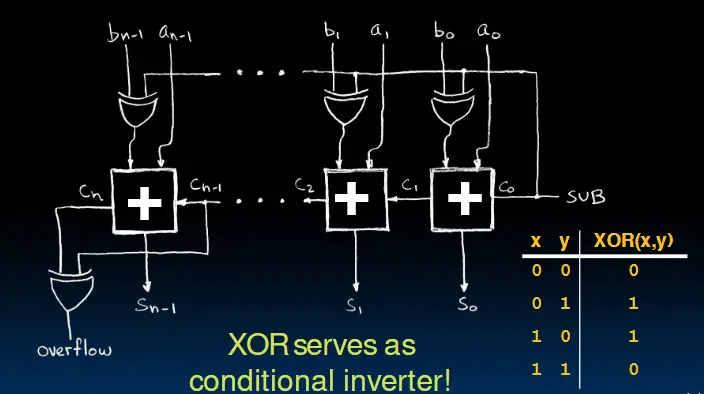
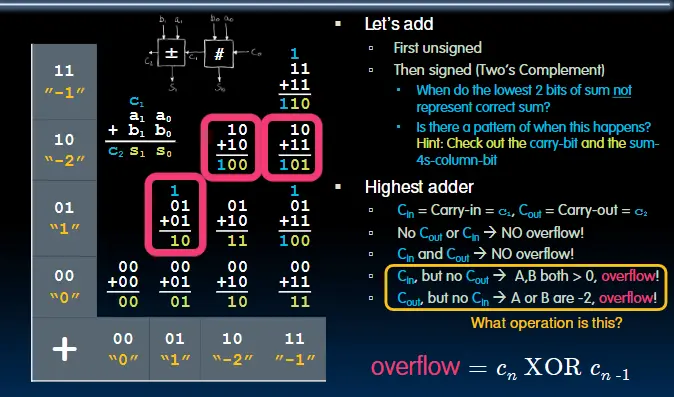 减法器的设计:减法可以视作加上一个负数。对于二进制补码数来说,翻转它的所有位,并加上1就能得到它的相反数。反转每一位的操作可以用XOR做到,加1的操作可以将$C_0$置1。在下图的设计中,只要将SVB置1,就可以完成以上两个操作(妙啊)。
减法器的设计:减法可以视作加上一个负数。对于二进制补码数来说,翻转它的所有位,并加上1就能得到它的相反数。反转每一位的操作可以用XOR做到,加1的操作可以将$C_0$置1。在下图的设计中,只要将SVB置1,就可以完成以上两个操作(妙啊)。
单周期CPU
- Processor(CPU):负责执行指令、处理数据,并协调内存、输入输出等部件的工作,通常由数据通路和控制单元构成。
- Datapath:处理器内部的功能单元集合(如ALU、寄存器、总线),负责数据的传输、运算和暂存,直接执行指令所需的底层操作。
- Control:通过生成时序信号协调数据通路的运作,解析指令并决定操作流程,确保各部件按正确顺序协同完成指令执行。
数据通路
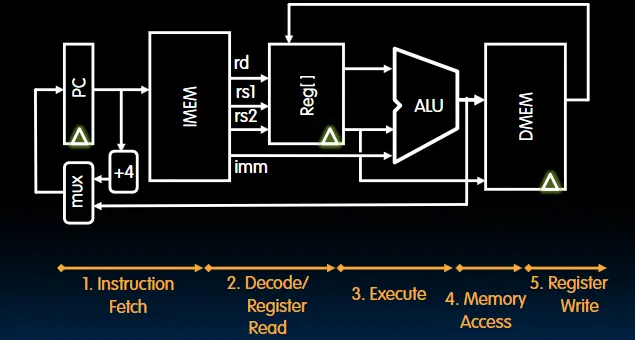
- 取指令(IF)
- 解指令(ID)
- 执行(EX)
- 访存(MEM)
- 回写(WB)
这五件事在一个时钟周期内完成。在上图的几个元件中,PC、寄存器堆、指令存储器与数据存储器是存储状态的。
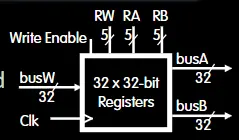 这是寄存器堆的示意图,RW为busW上的数据写入的目标寄存器的地址,RA、RB分别为读入到busA、busB上的寄存器数据的地址。Wirte Enable为写入使能。在一个时钟周期内能对寄存器堆中的2个进行读取,对1个进行写入。除了寄存器堆中的寄存器之外,PC也是一个32位寄存器。
这是寄存器堆的示意图,RW为busW上的数据写入的目标寄存器的地址,RA、RB分别为读入到busA、busB上的寄存器数据的地址。Wirte Enable为写入使能。在一个时钟周期内能对寄存器堆中的2个进行读取,对1个进行写入。除了寄存器堆中的寄存器之外,PC也是一个32位寄存器。
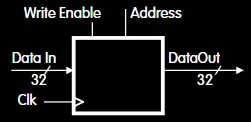 这是指令/数据存储器的示意图,如果只输入Address,则DataOut会直接输出对应地址的数据。如果Write Enable使能,则会将Data In读入到对应地址。实际上指令和数据存储器在同一物理存储器中。
这是指令/数据存储器的示意图,如果只输入Address,则DataOut会直接输出对应地址的数据。如果Write Enable使能,则会将Data In读入到对应地址。实际上指令和数据存储器在同一物理存储器中。
数据通路的具体结构
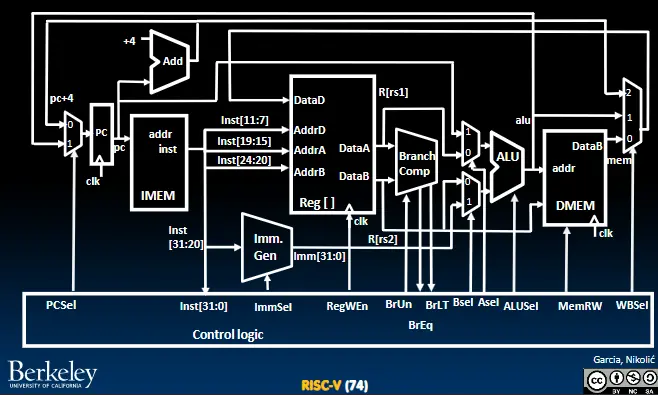
时序图
$$CriticalPaht = t_{clk-q}+max\{t_{add}+t_{mux},t_{IMEM}+t_{Imm}+t_{mux}+t_{ALU}+t_{DMEM}+t_{mux},t_{IMEM}+t{Reg}+t_{mux}+t_{ALU}+t_{DMEM}+t_{mux}\}+t_{setup}$$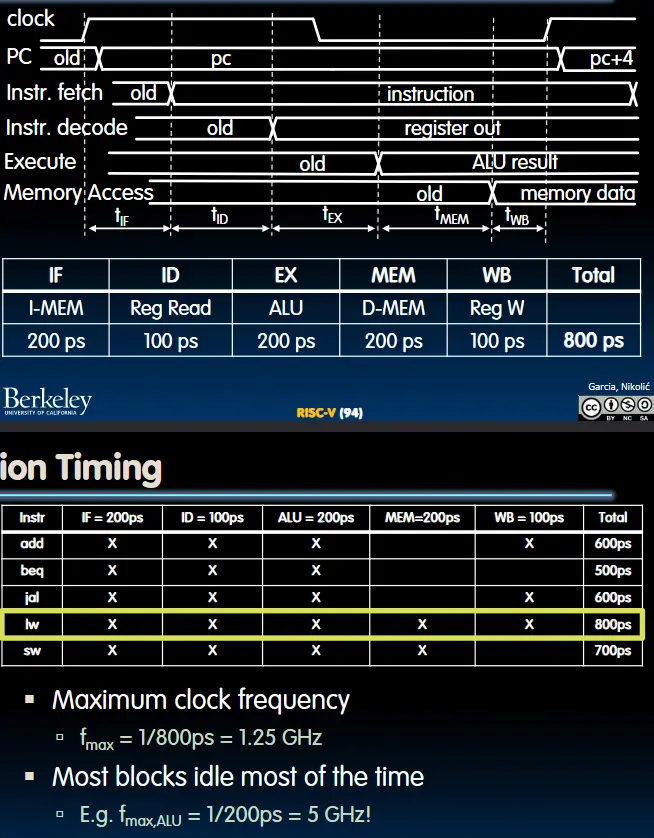
控制逻辑
控制与状态寄存器(CSR)
CSR相关指令
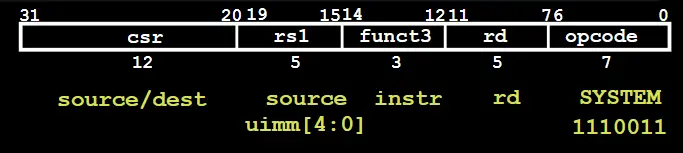 其中uimm是零扩展到32位的无符号数。
以下指令都是伪指令。
其中uimm是零扩展到32位的无符号数。
以下指令都是伪指令。
- csrrw, x0, csr, rs1
- 将rs1的内容写入csr
- csrrs/c rd, csr, rs1
- 将rs1的内容写入csr并将rd的内容设置到csr中
- csrrwi x0, csr, uimm
- 将立即数写入csr
- csrrs/ci rd, csr, uimm
- 将uimm的内容写入csr并将rd的内容设置到csr中
控制单元
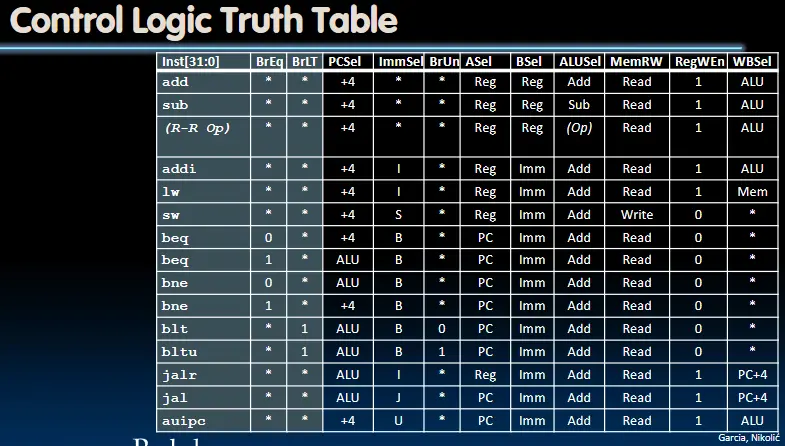 实现控制逻辑的方法:
实现控制逻辑的方法:
- ROM(Readonly Memory)
- 在ROM中预先存放控制信号,需要使用时直接读取(查表)
- 常用于CPU原型设计
- 组合逻辑
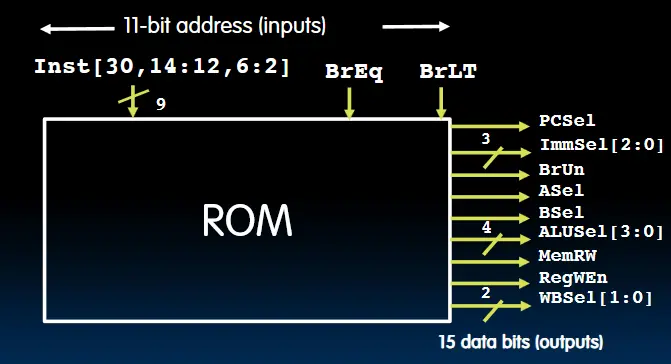
- 速度更快,成本更低 控制信号 从指令的opcode(inst[6:2])、funct3(inst[14:12])、funct7(inst[30])以及分支比较的结果BrEq、BrLT得来。
ROM
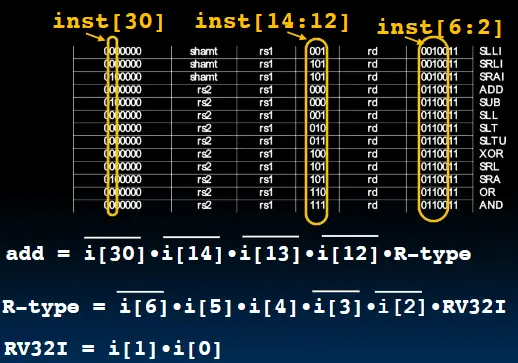
组合逻辑
示例:使用布尔代数解码add指令
流水线
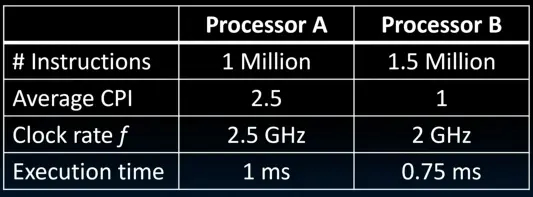
CPU性能的“Iron Law”
$$\frac{Time}{Program} = \frac{Instructions}{Program}\cdot\frac{Cycles}{Instruction}\cdot\frac{Time}{Cycle}$$CPU性能的决定因素:
- ISA
- CPI(Cycles Per Instruction)
- 时钟周期
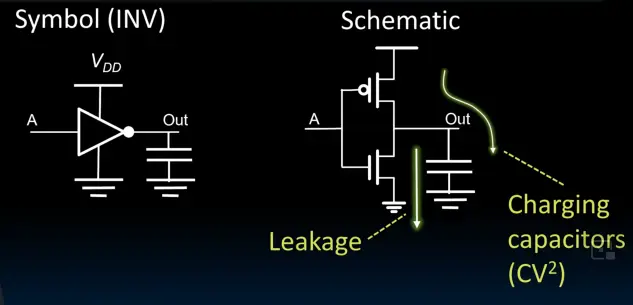
 在下面这个逻辑门中,漏电流消耗了30%能量(因为晶体管无法像理想的开关一样):
在下面这个逻辑门中,漏电流消耗了30%能量(因为晶体管无法像理想的开关一样):
流水线的结构
 在阶段直接插入寄存器来实现流水线:
在阶段直接插入寄存器来实现流水线:
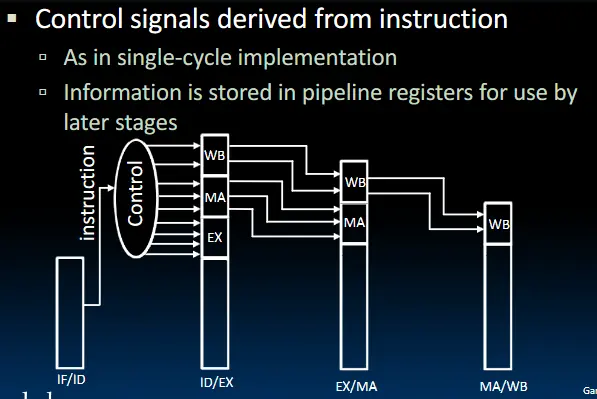
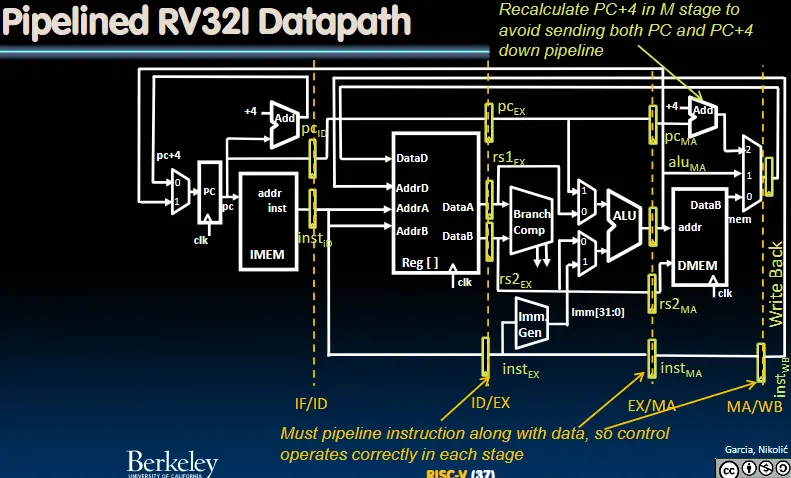 必要的控制字同样也要保存在寄存器中:
必要的控制字同样也要保存在寄存器中:
流水线中的冒险(Hazard)
通常有三种冒险:
- 结构冒险
- 需求的资源正在被使用
- 数据冒险
- 指令间的依赖关系
- 控制冒险
- 分支或跳转造成流水线上的下一条指令无效
结构冒险:两个或多个流水线上的指令同时需要访问单个物理资源。 解决方法1:使部分指令暂缓执行 解决放法2:增加更多物理资源(常用)
数据冒险:
- 寄存器访问
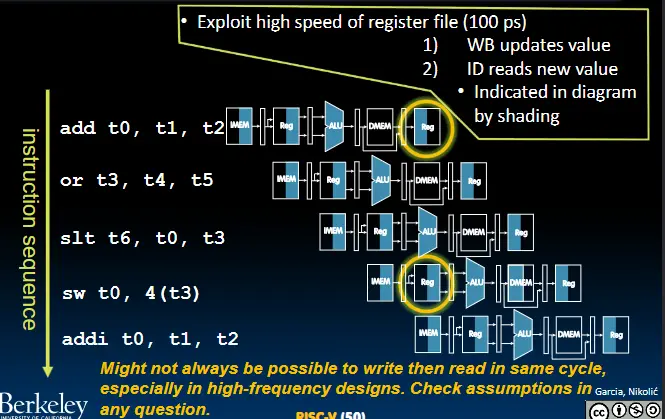
- ALU结果访问
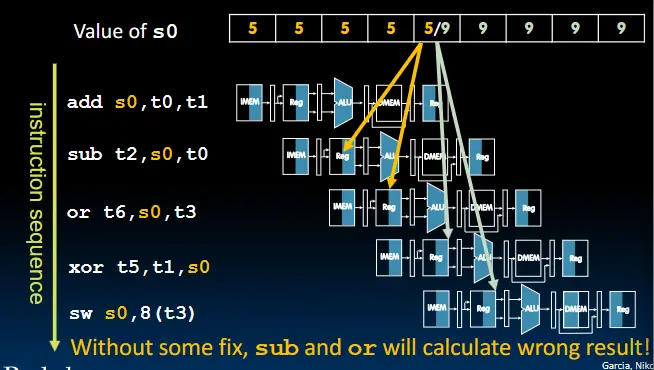 解决方法1:暂缓指令的执行
解决方法1:暂缓指令的执行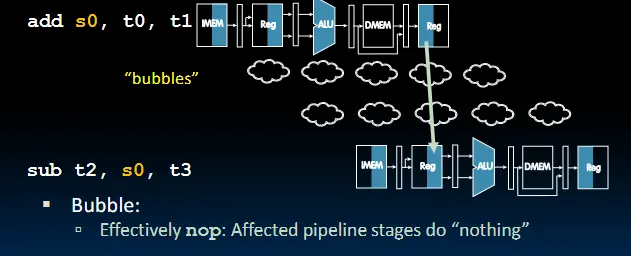 解决方法2:修改数据通路,使下一条指令无需执行到回写阶段(Forwarding Control Logic)
解决方法2:修改数据通路,使下一条指令无需执行到回写阶段(Forwarding Control Logic)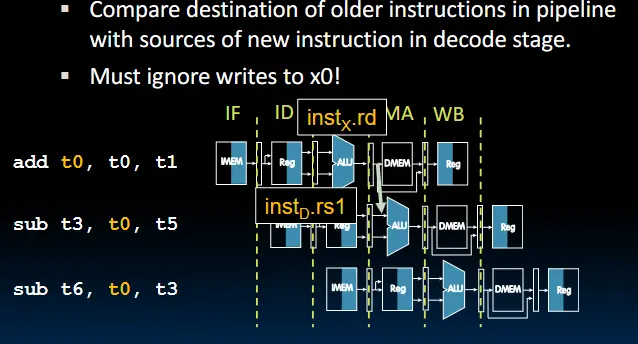
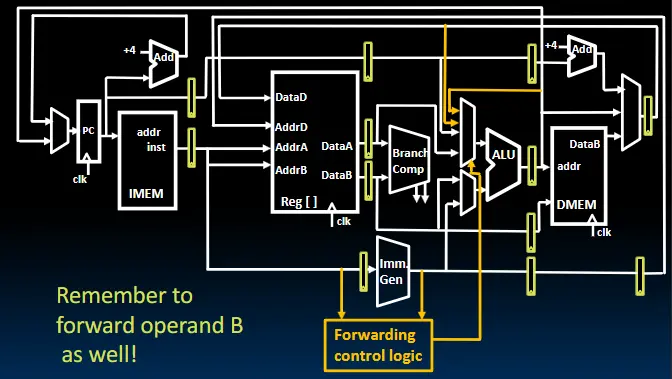
控制冒险:
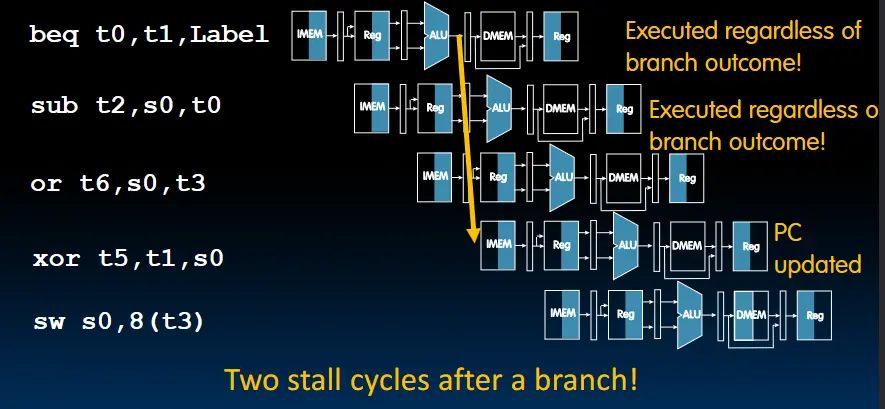 分支发生后,流水线上的后两条指令不应该被执行。
解决方法:在分支指令后暂停执行两个周期(插入两条nop指令)。
为了减少分支指令带来的暂缓执行问题,使用一种名为“分支预测”的技术,提前预测PC的下一个值。只有在预测错误时,才插入两条nop指令。
分支发生后,流水线上的后两条指令不应该被执行。
解决方法:在分支指令后暂停执行两个周期(插入两条nop指令)。
为了减少分支指令带来的暂缓执行问题,使用一种名为“分支预测”的技术,提前预测PC的下一个值。只有在预测错误时,才插入两条nop指令。
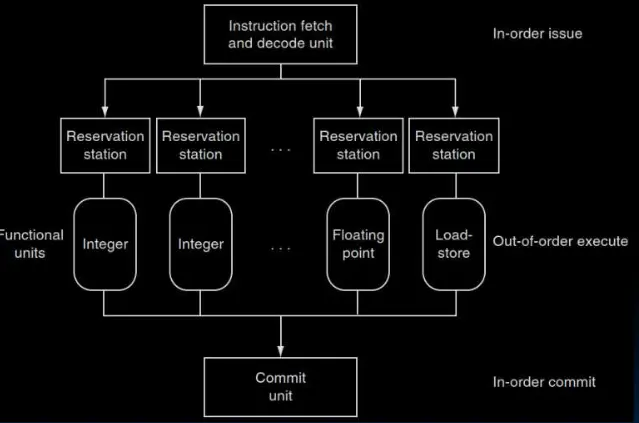
超标量处理器
超标量处理器具有多个执行路径,采用了“乱序执行”等方法使CPI在特定情况下可以低于1。